
从零开始的RPC开发旅程0x00 - 一切的前言————Netty
导语:Netty 一切的开端
RPC(Remote Procedure Call)远程过程调用,简单理解是一个节点请求另一个节点提供的服务,这其中就涉及到了网络通信,Java做网络通信这块,离不开Netty框架。
咱们后端程序员想要进阶,绕不开Netty。如果你想探索更底层的网络模型,同样绕不开Netty。网络通信编程,是通往神级程序员的必经之路,其中涉及到的知识浩渺如海,但同时也能让你得到技术升华。加更多班
那么问题来了,Netty到底是什么?
Netty是一款基于NIO(Nonblocking I/O,非阻塞IO)开发的网络通信框架。它极大地简化了TCP、UDP等网络编程的复杂性,是当前Java网络编程的首选框架。
接下来,咱们一起深入了解Netty背后的核心概念和技术原理!
一、理解IO模型:网络通信的基础
想象一下这个场景:应用A向应用B发送一条消息。这个看似简单的过程,背后涉及了哪些步骤呢?
- 应用A把消息发送到TCP发送缓冲区
- TCP发送缓冲区将消息发送出去,经过网络传递
- 消息到达B服务器的TCP接收缓冲区
- 应用B从TCP接收缓冲区读取数据
看起来很简单,但问题就出在最后一步:应用B如何稳定的从缓冲区读取数据?
1.1 阻塞IO:最简单但效率最低的模型
在上图中,应用B从TCP接收缓冲区接收数据的时候,会出现以下情况:
- 消息的发送不是一个持续状态,也就是说TCP接收缓冲区中可能没有B需要的消息
- B去TCP接收缓冲区拿取消息的时候,拿不到对应的消息
这下拿也不是,不拿也不是,好似咱们外卖苦等最后500m,心急如焚坐立不安…
于是,最初的网络模型——阻塞IO出现啦!
什么是阻塞IO?举个生活中的例子:你打电话给外卖小哥问订单到哪了,如果他让你别挂电话等着,直到他送到门口 - 这就是”阻塞”。你的时间被完全占用了,啥也干不了,只能傻等。
在计算机世界中,阻塞IO就是:应用发起读取数据的请求,如果数据没准备好,应用就一直等待,直到数据准备好为止。这期间应用啥也干不了!
1 | 应用:我要读数据! |
真实流程:
- 应用进程向内核发起recvfrom读取数据
- 准备数据报(应用进程阻塞)
- 应用进程将数据从内核复制到应用空间
- 复制完成后,返回成功提示
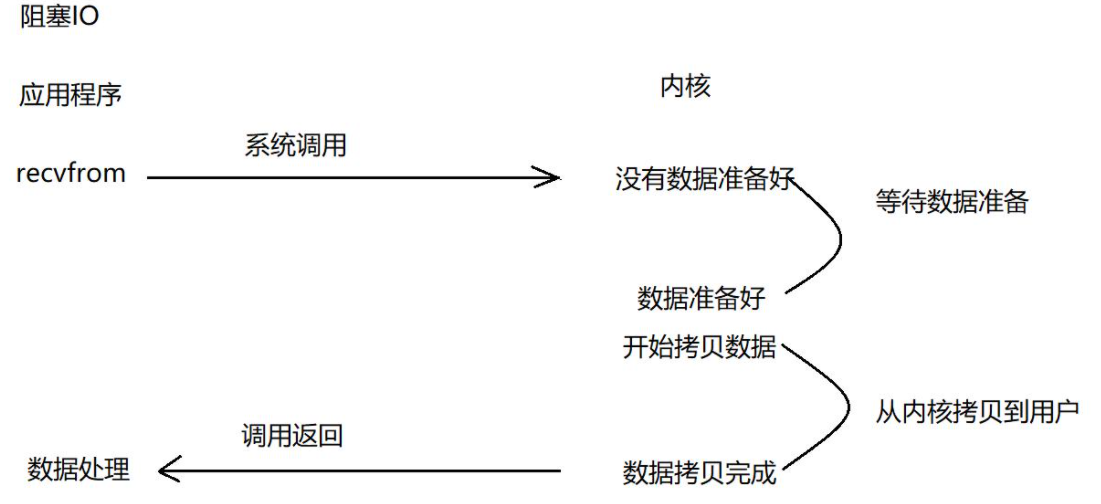
最初的阻塞IO,就像是咱们在寒冬腊月里站在公交站台苦等公交车一样。冷风呼啸,鼻尖冻得通红,却只能死死站在原地一动不动地等。
于是,非阻塞IO概念出现了!这就像是咱们发现了个聪明办法:在公交站旁开了家暖和的咖啡店,可以进去喝杯热饮,暖和身子。隔一会儿探头看看外卖小哥到了没,没到就继续回咖啡店享受温暖。不用傻站着挨冻,还能干点别的事儿,多好!
1.2 非阻塞式IO:轮询的方式
非阻塞IO就像你隔一会就给外卖小哥打个电话问到哪了,打完电话你可以继续做自己的事情。
在非阻塞模式下,应用程序会不断地询问内核数据是否准备好,而不是一直等待:
1 | 应用:我要读数据! |
真实流程:
- 应用进程向内核发起recvfrom读取数据
- 没有数据报准备好,内核即刻返回EWOULDBLOCK错误码
- 应用进程继续向内核发起recvfrom读取数据
- 已有数据包准备好就进行一下 步骤,否则内核还是返回错误码
- 数据包准备好了,将数据从内核拷贝到用户空间
- 复制完成后,返回成功提示
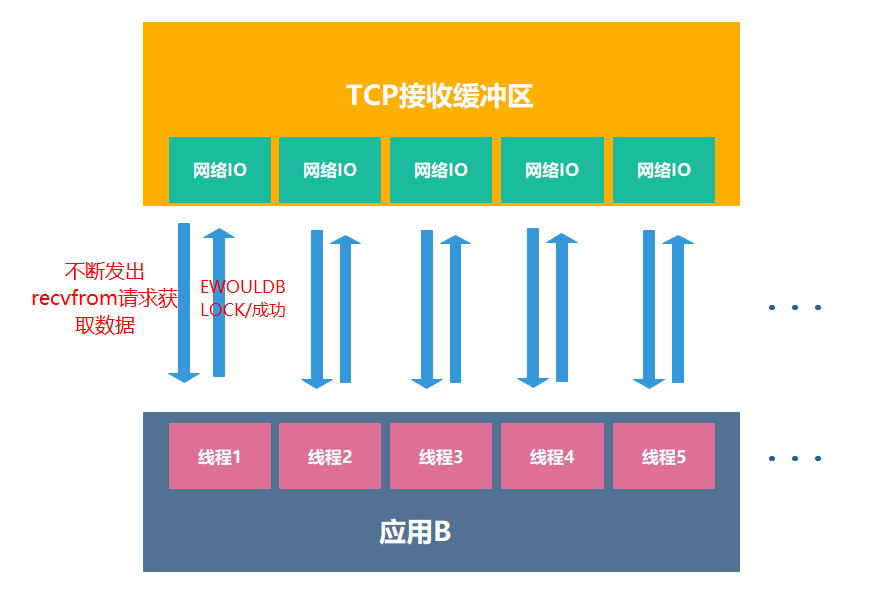
但是,轮询式的非阻塞IO,就像是我们不停打电话催外卖,小哥反复停下来接电话,不管怎么想,都觉得既浪费资源,又很不合理吧,有没有办法不用一直催就能知道外卖进度呢?
于是,一个更合理的模型概念,IO复用出现了!
1.3 非阻塞式IO:一个人监控多个任务的模式(IO复用)
如果有上百个连接需要监控,难道要创建上百个线程分别去问”数据好了吗”?这也太浪费资源了!
于是有了IO复用模型:由一个或少量线程不断去检查多个连接上的数据状态,只有当数据准备好时,才会通知应用程序进行处理。
这就好比,出现了一个叫”饱了吗”的外卖平台,我们不再需要频繁打电话催外卖小哥,而是平台帮我们监控所有订单的状态。你同时点了烤鸭、火锅、奶茶和蛋糕,不用分别给四家店打电话询问进度,”饱了吗”平台会同时监控这四个订单的状态。
这样,一个”饱了吗”平台(即一个线程)就能同时监控上百个订单(连接),大大节省了人力和电话费(线程资源)。而且服务员不用频繁打断你的休息时间,只在真正需要你注意的时候才会通知你。
在Linux中,这种模式通过select、poll和epoll等机制实现。其中epoll效率最高,就像是有了一个AI智能客服,不用轮询每个网络IO,而是内核主动推送重要通知
1 | 监控线程:我要监控这100个连接的状态! |
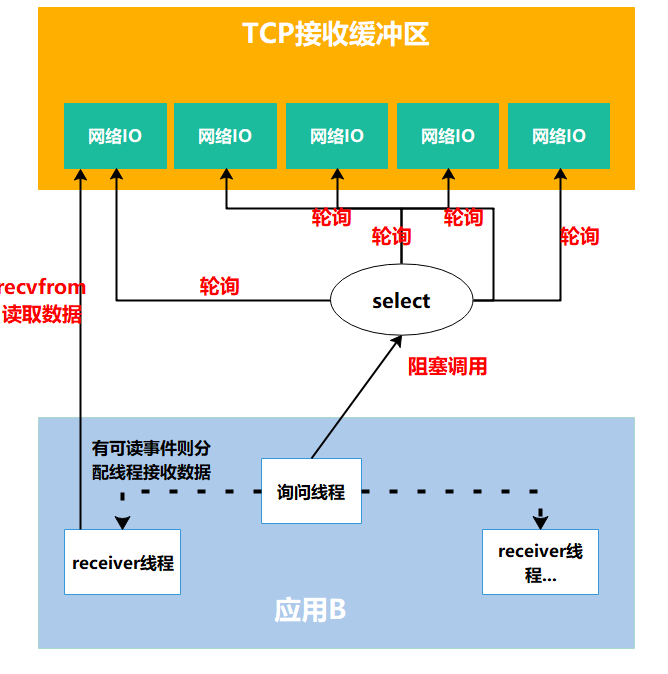
真实流程:进程通过将一个或多个fd(fd文件描述符,linux系统把所有网络请求以一个fd来标识)传递给内核中的select程序,阻塞在select操作上,select帮我们侦测多个fd是否准备就绪,当有fd准备就绪时,select返回数据可读状态,应用程序再调用recvfrom读取数据
复用IO的基本思路就是通过select或poll、epoll 来监控多fd ,来达到不必为每个fd创建一个对应的监控线程,从而减少线程资源创建的目的。
不过,外卖小哥似乎还是会被催单,只是这个催单的电话是从更快更高效的”饱了吗”打过去的…咱们能不能让小哥歇歇欸,让他到了自己打电话?
终于,外卖小哥忍不住了,信号驱动IO出现了…
1.4 非阻塞式IO:被动接收通知(信号驱动)
信号驱动IO则更进一步,应用程序不需要不断地询问或等待,而是注册一个信号处理器,当数据准备好时,内核会主动通知应用程序
就好比外卖小哥再也不用被平台和用户催单了,而是要求你留一个电话号码,到了点就给你打电话,其他时间你去打游戏也好,修BUG也好,总之不用再催啦!
1 | 应用:内核,数据准备好了请通知我,我去干别的了。 |
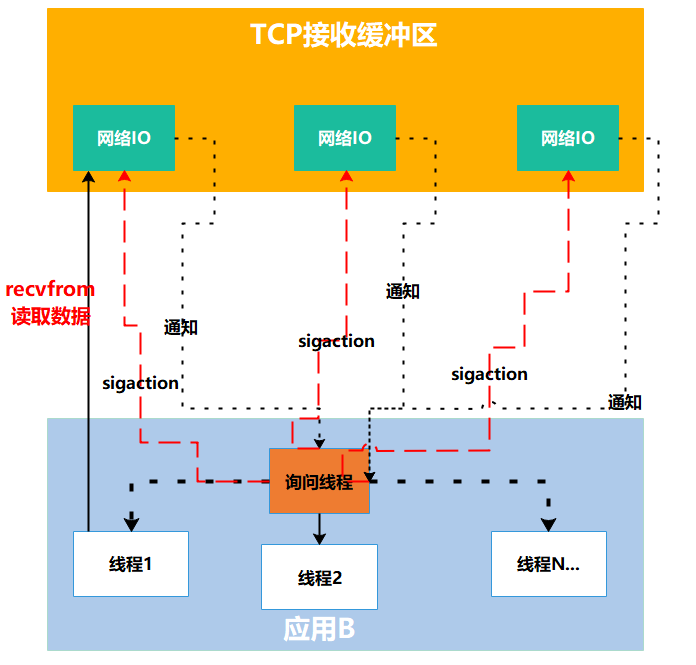
术语描述:首先开启套接口信号驱动IO功能,并通过内核调用sigaction执行一个信号处理函数,此时请求即刻返回,当数据准备就绪时,就生成对应进程的SIGIO信号,通过信号回调通知应用线程调用recvfrom来读取数据。
这种模式下,外卖小哥(内核)和顾客(应用程序)都轻松多了。顾客不用担心错过外卖,小哥也不用被不停地催单,双方都保持了良好的体验。
在计算机术语中,这种机制是通过信号(signal)实现的,应用程序告诉内核”有消息就发信号给我”,然后就可以放心去做别的事情了。当内核发现数据就绪,就会发送一个SIGIO信号通知应用程序,应用程序收到信号后再去处理数据。
1.5 异步式IO:全程无需关心
前面的模型,应用程序都需要自己去读取数据。而异步IO模型中,应用程序只需发起一个读操作,然后继续做其他事情,内核不仅会等待数据准备好,还会主动将数据从内核复制到应用程序缓冲区,避免终端开销的同时,还会及时通知应用程序。
好比,以前的外卖是咱们自己下楼拿,而现在会告诉外卖小哥一个门牌号,小哥亲自送到家门口,叮咚一声门铃,外卖就到你家了!
1 | 应用:内核,我需要这个数据,准备好了直接给我放在这个地址。 |
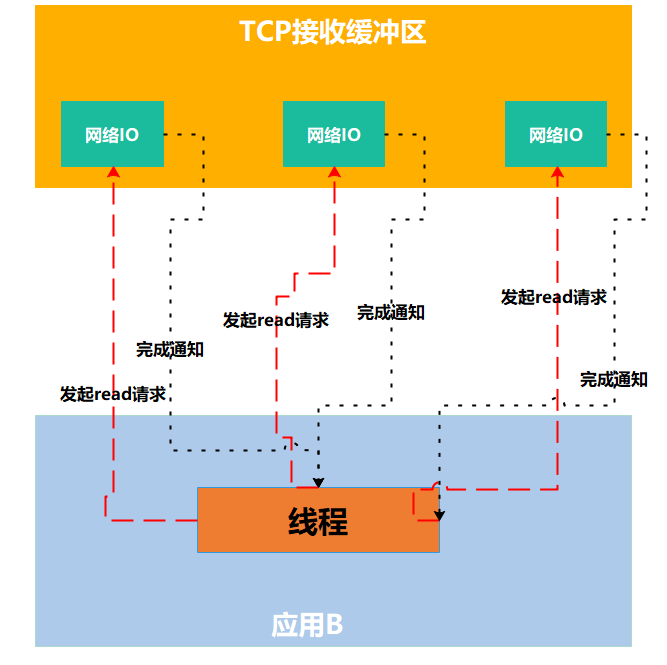
真实流程: 应用告知内核启动某个操作,并让内核在整个操作完成之后通知应用。这种模型与信号驱动模型的主要区别在于,信号驱动IO只是由内核通知我们合适可以开始下一个IO操作,而异步IO模型是由内核通知我们整个操作什么时候完成。
二、BIO、NIO、AIO:Java中的三种IO模式
2.1 BIO(Blocking I/O):同步阻塞
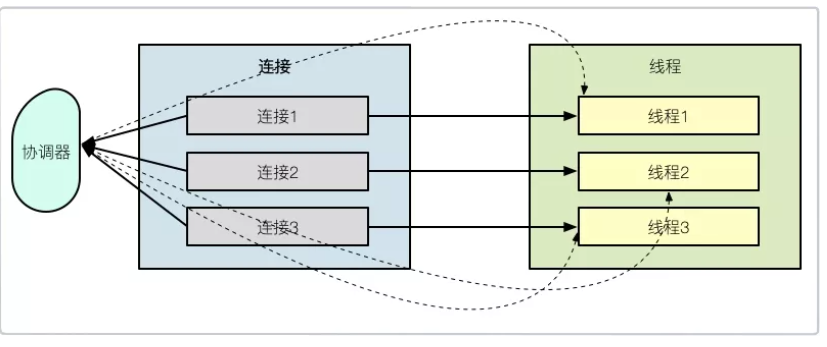
BIO就像是古早时期的”一对一专车服务”,每来一个客人,就得安排一名司机专门负责。10个客人就需要10个司机,1000个客人就需要1000个司机!
咱们先复习两个基本概念:
阻塞与非阻塞:阻塞就是你发起请求后必须在原地死等结果;非阻塞则是发起请求后可以立即去做别的事
同步与异步:同步是整个过程都需要你亲自参与;异步是你只负责发出指令,等结果通知就行
来看个简单的BIO服务器示例:
1 | // BIO服务器示例 |
使用nc进行测试:
1 | # nc64 -v localhost 8888 |
每当有一个连接到来,就必须开启一个线程专门处理。想想看,如果同时有1000个连接,那就需要创建1000个线程!这对服务器资源简直是场灾难…
虽然单个连接的处理速度不慢,但在高并发场景下,大量线程会导致服务器资源耗尽,性能急剧下降。这就是为什么我们需要更高效的NIO模型,尤其是在处理大量并发连接的场景下。
记住这个结论:单个连接处理,BIO和NIO差别不大;但在高并发场景下,NIO的资源利用率远高于BIO。就像一个服务员可以同时照看多桌客人,而不是只能盯着一桌!
2.2 NIO(Non-blocking I/O):同步非阻塞
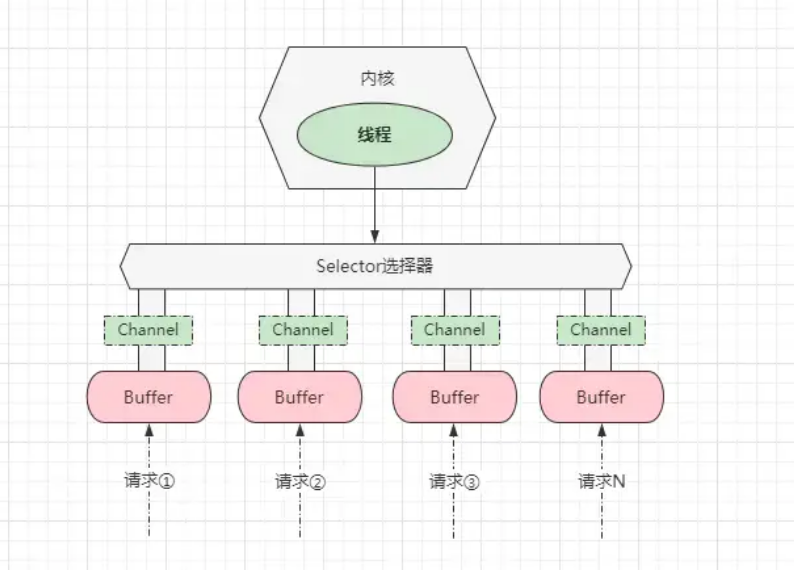
Java NIO (Non-Blocking IO) 是Java SE 1.4引入的,专为网络传输效能优化的功能。它是一种非阻塞同步的通信模式。NIO的核心组件包括:
- Channel(通道)
- Buffer(缓冲区)
- Selector(选择器)
咦,NIO听上去好高级,它到底解决了什么问题呢?
想象一下传统餐厅的服务方式:每张餐桌配一名服务员(BIO模式)。现在咱们升级为”共享服务员”模式:一名服务员可以同时照看多张餐桌,只有当客人真正需要点餐或结账时才去服务。这就是NIO的核心思想!
那么,这么高级的餐厅究竟是怎么实现的呢?
2.2.1 Select、Poll和Epoll三兄弟
NIO主要有三种实现:select,poll,epoll。这三种都是IO多路复用的机制。
Select:年龄最大的大哥
1 | int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); |
Select就像是餐厅里那个经验丰富但方法老旧的胡子大厨,他需要定期查看所有的锅是否煮好了,无论有没有菜在煮。虽然老当益壮,但就是精力不足…
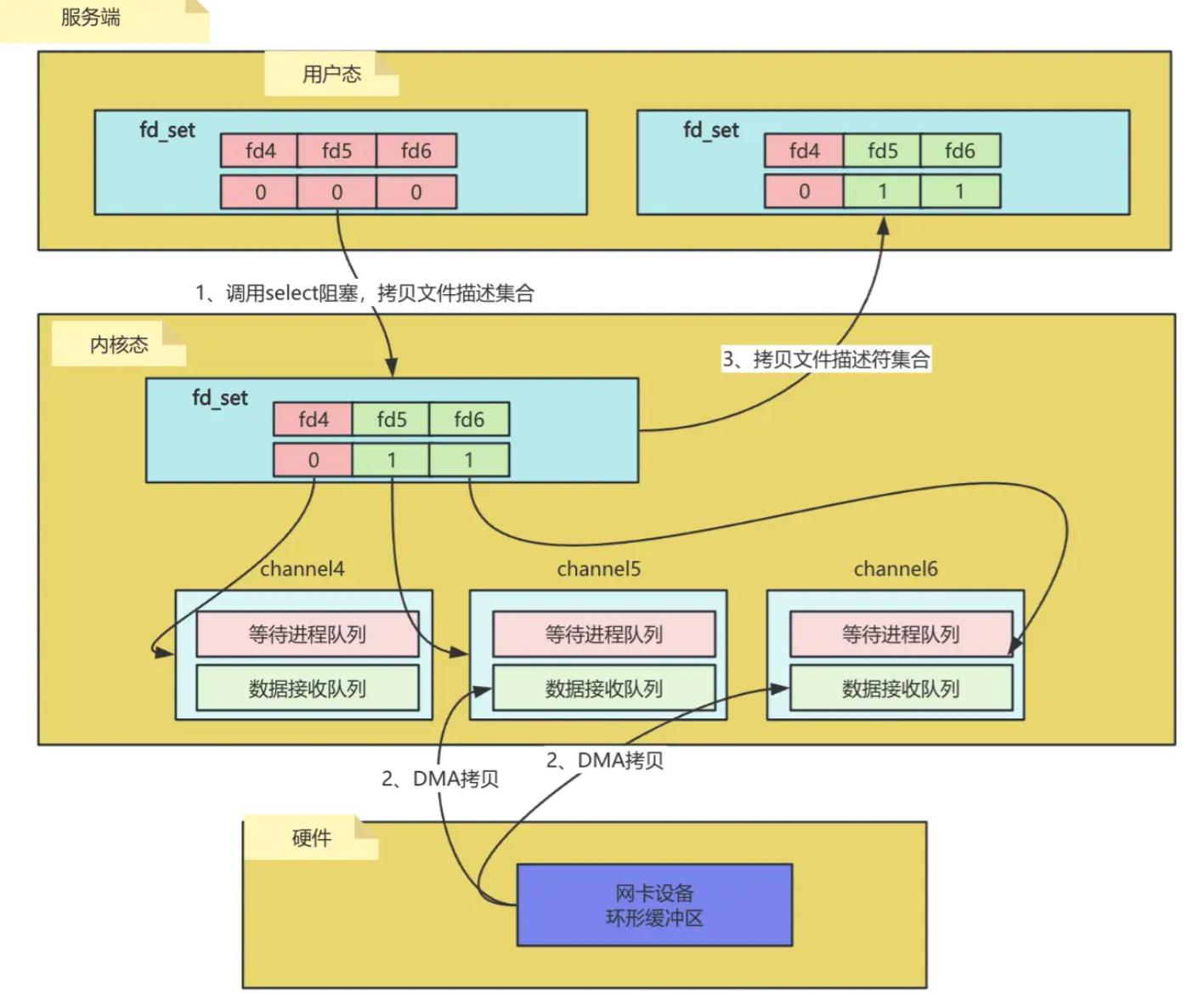
fd_set是select机制中用于表示文件描述符集合的位图结构。每个位对应一个文件描述符,比如端口号;内核在定位到这些连接的时候,就是通过fd进行寻址,当值为1往往表示该描述符需被应用监控和通讯。
执行步骤
- 将当前进行所有的描述符都从用户态拷贝到内核态。注意该方法为阻塞方法,需要一直等待。
- 内核会检测fd_set中的fd是否有已经就绪/超时的;这里fd会绑定channel对象;
- 当数据通过
DMA拷贝从网卡设备拷贝到数据接收队列;把对应文件描述符标识置为1;- 文件描述符集合返回给用户态;唤醒等待队列中的进程/线程;
- 用户态循环遍历查看哪个fd已经就绪了。
缺点:
同时监控的连接数(bitmap)有限制(一般为1024,64位计算机为2048)
监控的连接(fd_set)不可重复使用,每次都需要新建,且每次调用都需要把连接从用户态复制到内核态
select函数返回后需要重新遍历所有连接来找出就绪的连接,效率低
眼看大哥垂垂老矣,二哥身先士卒,于是Poll应声而出!
Poll:改良版的二哥
1 | struct pollfd { |
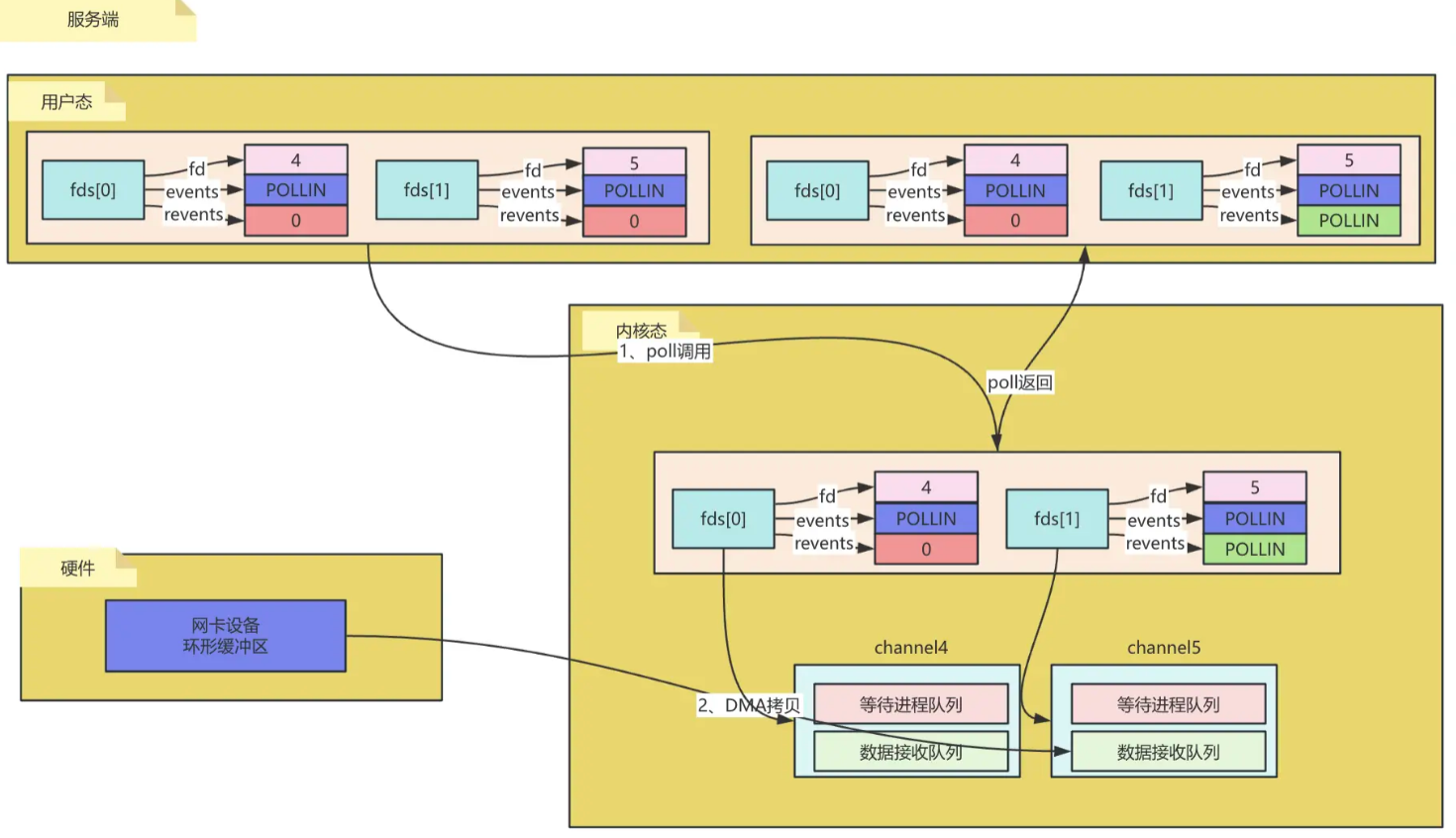
执行步骤:
- 将当前进程/线程全部描述符封装态pollfd,一次性从用户态拷贝到内核态;
- 在内核遍历fds,查看是否有就绪的;
- 当有就绪fd时把对应pollfd中的revents更改为对应标识,例如已可读了,则更改为
POLLIN,并返回已就绪fd的数量给用户态;- 用户态循环遍历每个fd,如果发现revents的标识为events中需要关注的标识则把revents再次置为0并开始处理业务逻辑。
poll解决了select中存在的:
bitmap有大小限制,一般32位操作系统为1024,64位操作系统为2048;fd_set不可重复使用,每次都需要新建;
但还存在频繁拷贝pollfds、以及每次返回值都需要重新遍历一遍查看具体哪个fd就绪了。
- 用户态、内核态需要反复拷贝fd_set;
- poll函数返回的是有几个描述符已经就绪了,需要再次遍历时间复杂度为O(n)。
Poll就是Select的青春升级版,主要是在fd上做了包装优化,用状态变化取代了频繁的创建和销毁,并取消了连接数量的限制,但本质上还是需要遍历所有连接。
感觉Select和Poll都还是没解决根本问题嘛…
确实!它们都有一个共同的缺点:当监控的连接数量增多,性能线性下降。这就好比服务员要不断巡视餐厅的每一桌,即使大部分客人还在看菜单不需要服务。
于是,厚积薄发的三弟悄然登场…
Epoll:C位出道的三弟
1 | int *epoll_create*(int *size*); *// 创建epoll句柄* |
epoll就像一个智能餐厅管理系统:不是服务员挨桌检查(select/poll的轮询方式),而是每桌客人有专属呼叫器(注册的fd),需要服务时按下呼叫键(IO就绪),系统立即通知服务员哪桌需要服务(事件通知)。这种”按需服务”模式让一个服务员能高效管理成百上千桌客人,无需浪费时间查看不需要服务的桌子。
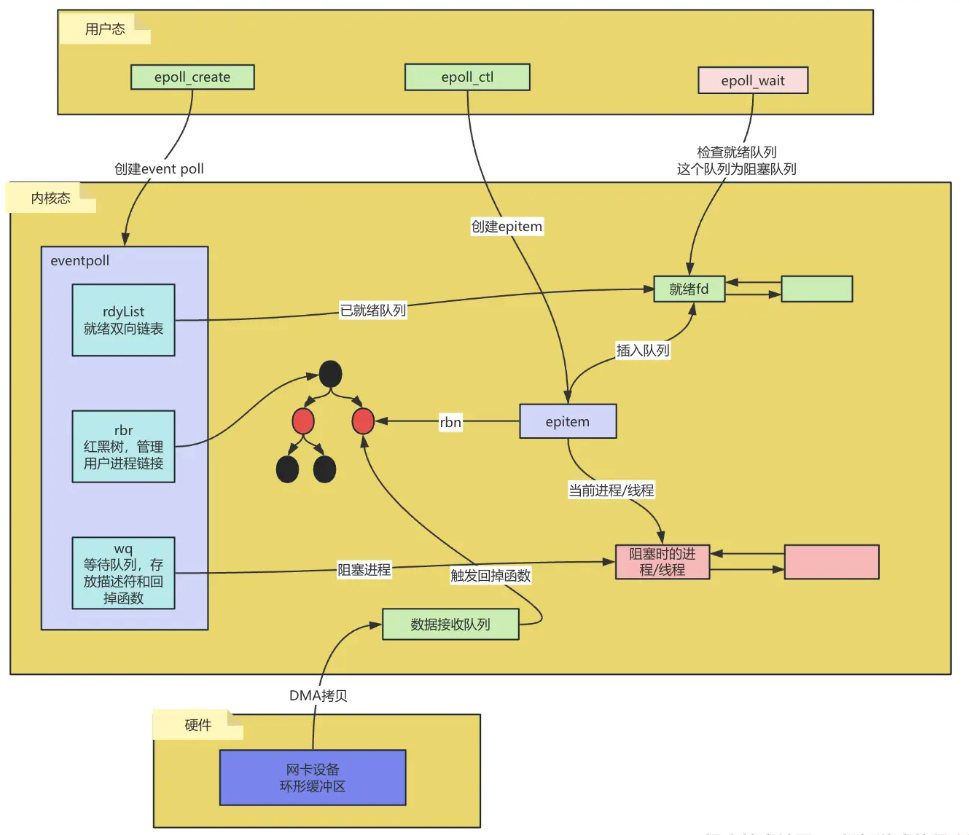
整体步骤:
- 调用
epoll_create创建eventpoll; - 调用
epoll_ctl创建epitem,并把epitem中的各个属性都赋值到上述的eventpoll中; - 调用
epoll_wait,先检查rdylist中是否有就绪的fd,如果有则直接返回,如果没有则阻塞等待,并把当前进程/线程放到wq队列中等待。 - 当有数据到达并且拷贝到数据接收队列时,会触发
epoll_event_callback函数,该函数根据sockid从红黑树中找到对应的epitem节点,把它放到就绪队列中并唤起wq队列中阻塞的进程。
Epoll是三兄弟中最年轻但能力最强的,它巧妙地解决了前两者的问题:
无限制:能监控的连接数量没有上限
效率高:不需要每次都复制所有连接信息
主动通知:采用事件驱动机制,不需要轮询所有连接
按需处理:只返回有事件发生的连接,无需遍历
同时epoll还提供了水平触发LT、边缘触发ET两种发出机制:
水平触发(level trigger):只要底层有事件就绪,只要不处理就会不断触发epoll回调函数;
边缘触发(edge trigger):与之前的event相比,如果event发生改变才会触发epoll回调函数。
这不就是我们梦寐以求的服务员吗?客人招手才去服务,不浪费精力!
也正是因此,Java的NIO,在Linux上底层是使用epoll实现的!
2.2.2 NIO的Selector案例
NIO通过Selector实现了一个线程管理多个Channel的操作,大大提高了IO效率。
1 | // NIO示例代码 |
等一下,这里的select()方法不是也在阻塞吗?没错,但这个阻塞和BIO的阻塞不同:
阻塞的对象不同:
BIO中:每个线程阻塞在一个连接上,1000个连接就需要1000个线程阻塞
NIO中:一个线程的select()阻塞可以同时管理1000个连接
阻塞的触发条件不同:
BIO中:每个read()必须等待数据到达才返回
NIO中:只要有任意一个Channel有事件发生,select()就会立即返回
阻塞的效率不同:
BIO中:每个阻塞线程都消耗系统资源,且不同线程间的切换开销大
NIO中:一个阻塞可以”顺便”处理多个事件,资源利用率高
阻塞的可控性不同:
BIO中:阻塞是被动的,完全受制于网络IO
NIO中:可以设置超时时间,实现可控的阻塞
这种设计使得NIO在高并发场景下有巨大优势——系统资源消耗不再随连接数线性增长,而是与活跃连接数相关。就像一个服务员不是在每桌前单独等待,而是在一个集中的地方等待任意桌的呼叫,一旦有呼叫就可以处理所有需要服务的桌子。
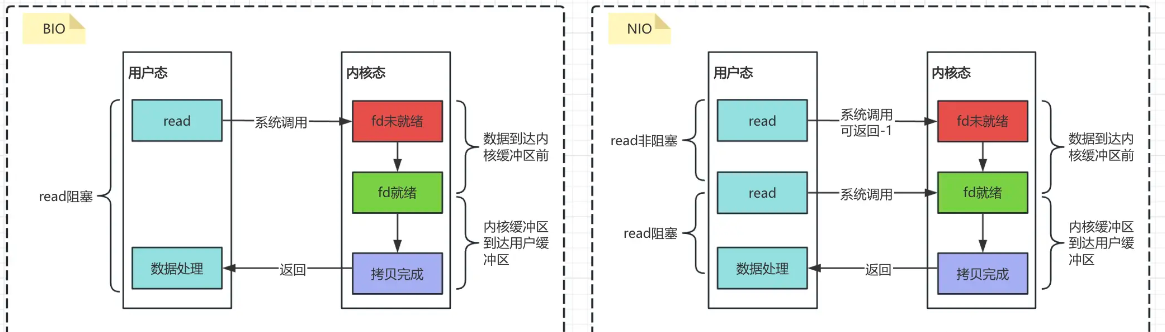
这样,以牺牲服务员(selector)一个人的代价,换来所有消费者的等餐自由,真实可喜可贺,可喜可贺啊!(服务员:大哭
2.3 AIO(Asynchronous I/O):异步非阻塞
AIO是Java 1.7引入的异步IO模型,应用发起IO操作后,不需要等待也不需要轮询,而是通过回调函数在IO操作完成后被通知
1 | // AIO示例代码 |
“回调地狱”来了!是不是看着有点眼晕?这就是AIO的缺点之一:代码复杂度较高。
AIO模型理论上性能是会提升的,但它现在发展的不太好。那部分对数据进行自动读取的操作,总得有地方实现,不在框架里,就得在内核里。Netty的NIO模型加上多线程处理,在这方面已经做的很好,编程模式也非常简单。所以,市面上对AIO的实践并不多。
三、Reactor模式:高性能网络编程的灵魂
上面的例子中,都是使用的java的原生IO模式,而本期的Netty是基于Reactor模式实现的NIO。
那么什么是Reactor模式?它和刚刚讲的NIO又有什么区别?
嗯…这个问题问得好!说白了,NIO是Java提供的底层API,而Reactor是基于这些API构建的一种设计模式。就像是,NIO给了我们砖头和水泥,而Reactor则是教我们如何盖出一栋漂亮的房子!
想象一个大型购物中心的客服部门:
原生NIO:就像只有一个服务台和一名客服人员。这名客服既要接待新客户,又要处理老客户的问题,还要亲自去库房取货,一个人忙得团团转。虽然比BIO的”专人专岗”节省了人力,但效率还是有限。
Reactor模式:则是对购物中心进行了智能化改造。设置了专门的接待区、咨询区和取货区,每个区域都有专职人员。客户进门后被导向不同区域,整个流程更加高效顺畅。
Reactor模式的核心思想是:将IO事件的监听和处理分离,并按照事件类型分发到不同的处理器上。
这样一来,程序的结构更清晰,职责更分明,而且能够更充分地利用多核处理器的优势。难怪Netty这么厉害!
而常见的Reactor线程模型有三种:
- Reactor单线程模型
- Reactor多线程模型
- 主从Reactor多线程模型
3.1 Reactor单线程模型
Reactor单线程模型,指的是所有操作(接受连接、读写数据)都在同一个NIO线程中完成:
1 | 一个线程 = 接受连接 + 读取数据 + 业务处理 + 发送响应 |
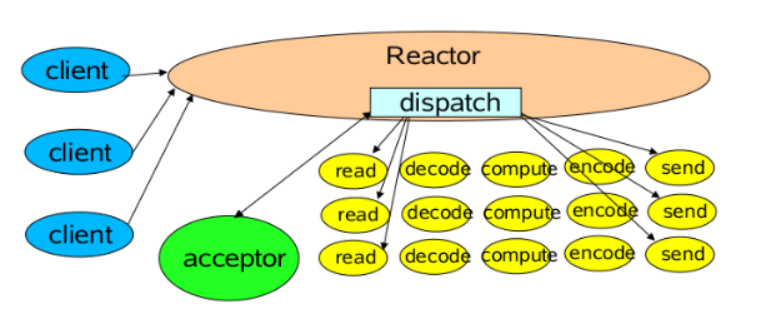
单线程模型不能充分利用多核资源,所以实际使用的不多
优点:简单
缺点:无法充分利用多核CPU,性能有限
这不就是用宝马车送外卖吗?一台8核CPU只用1个核心,其他7个核心闲着看戏,这资源浪费得也太夸张了吧!现在谁家服务器不是多核的?单线程模型简直就是拿着火箭当自行车骑…
所以,为了不让那么多CPU核心闲着尴尬,咱们有了:
3.2 Reactor多线程模型
Reactor多线程模型与单线程模型最大区别,就是有一组NIO线程专门处理I/O操作:
1 | 线程A = 接受连接 |
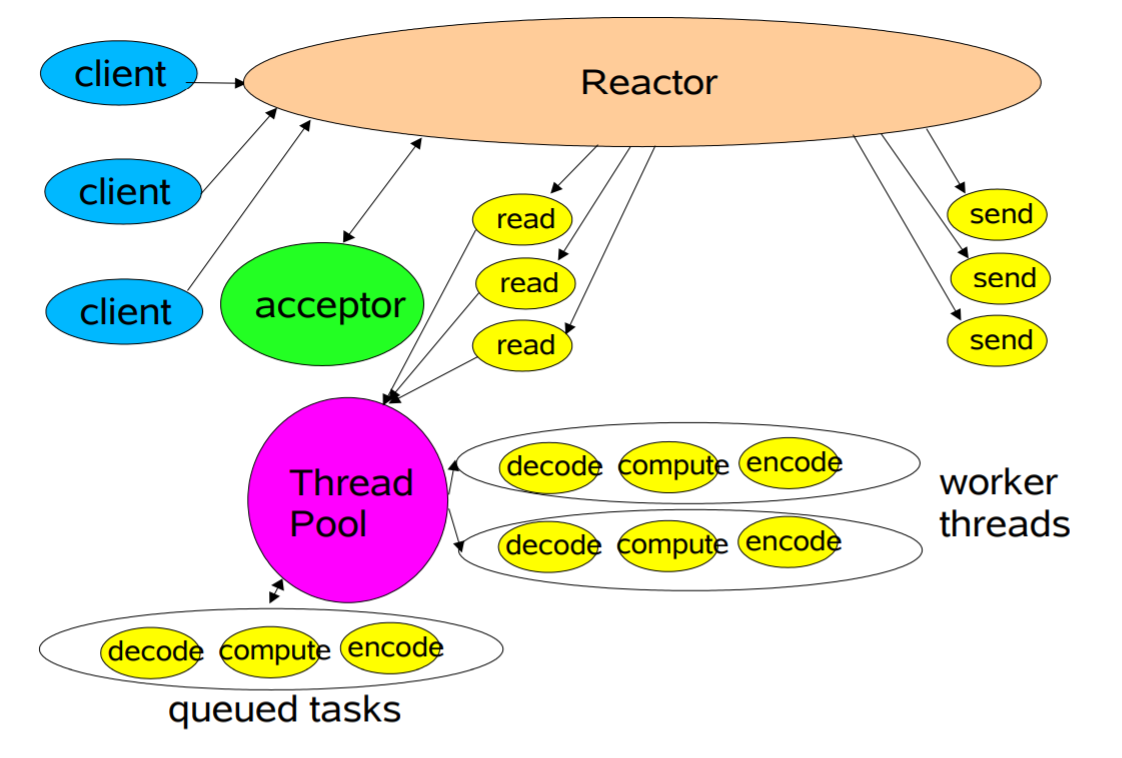
单线程模型不能充分利用多核资源,所以实际使用的不多
优点:能够充分利用多核CPU
缺点:在高并发场景下,接受连接的线程可能成为瓶颈
这种设计有个很大的优势:即使某些连接的处理很耗时(比如客人点餐慢),也不会影响其他客人的体验,因为有足够多的服务员同时工作。
不过,如果餐厅生意太好,门口排队的人太多,一个前台小姐姐可能忙不过来,这就成了新的瓶颈。毕竟就算厨师再多,如果客人进不来,再好的菜也没人吃啊!
当高并发请求袭来,单线程的Acceptor可能会成为性能瓶颈。这时候,我们就需要更先进的模式了…
3.3 主从Reactor多线程模型
相比Reactor多线程模型,主从Reactor多线程模型进一步将接受连接的工作也做成线程池:
1 | 线程池A = 接受连接 |
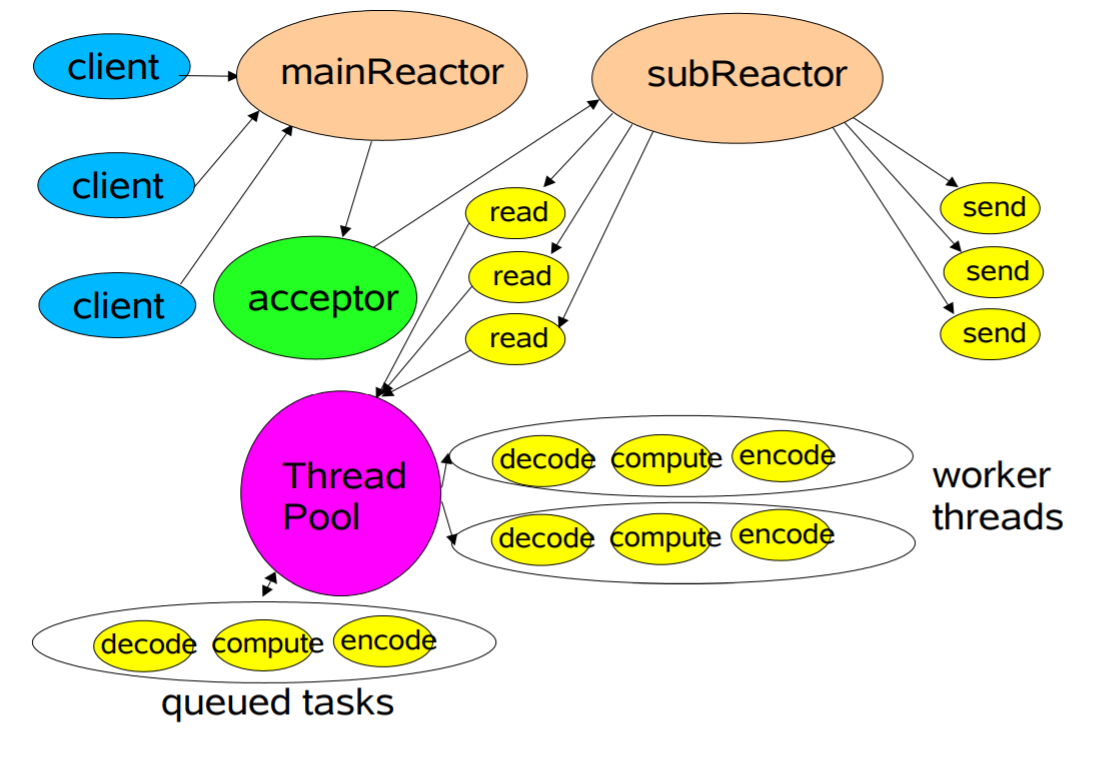
通常subReactor个数上与CPU核数相同
这种模式的基本工作流程为:
Reactor 主线程 MainReactor 对象通过 select 监听客户端连接事件,收到事件后,通过 Acceptor 处理客户端连接事件。
当 Acceptor 处理完客户端连接事件之后(与客户端建立好 Socket 连接),MainReactor 将连接分配给 SubReactor。(即:MainReactor 只负责监听客户端连接请求,和客户端建立连接之后将连接交由 SubReactor 监听后面的 IO 事件。)
SubReactor 将连接加入到自己的连接队列进行监听,并创建 Handler 对各种事件进行处理。
当连接上有新事件发生的时候,SubReactor 就会调用对应的 Handler 处理。
Handler 通过 read 从连接上读取请求数据,将请求数据分发给 Worker 线程池进行业务处理。
Worker 线程池会分配独立线程来完成真正的业务处理,并将处理结果返回给 Handler。Handler 通过 send 向客户端发送响应数据。
一个 MainReactor 可以对应多个 SubReactor,即一个 MainReactor 线程可以对应多个 SubReactor 线程。
这种模式被称为”主从Reactor多线程模型”,也是Netty默认的工作模式。
在这种架构下,无论是接待、服务还是业务处理,都不再有单点瓶颈。即使是”双十一”级别的客流量,餐厅也能有条不紊地运转。
这也是为什么Netty默认采用主从Reactor多线程模型 - 它就是为高并发而生的!每个连接从接入到处理,都有专门的线程团队负责,既避免了资源浪费,又确保了极致性能。
咱们的服务器终于可以撑起”双十一”了!不管多少用户同时涌入,系统都能稳如泰山。这就是多核时代的正确打开方式!
四、Netty框架:让网络编程变得简单
4.1 为什么选择Netty?
原生Java NIO存在以下问题:
- API复杂,使用麻烦
- 需要自行处理各种网络问题(断连重连、半包读写等)
- JDK NIO的bug(如epoll bug导致CPU 100%)
- 需要深入理解多线程和网络编程
而Netty解决了这些问题:
- API简单易用
- 功能强大,预置多种编解码功能
- 高性能,经过大规模商业验证
- 社区活跃,持续更新
4.2 Netty核心组件
- EventLoop和EventLoopGroup:事件循环,用于处理Channel的IO操作
- Channel:网络连接的抽象,如NioSocketChannel
- ChannelHandler:业务处理器,处理数据的读写
- ChannelPipeline:ChannelHandler的容器,形成处理链
- Bootstrap/ServerBootstrap:启动器,用于配置Netty程序
4.3 Netty服务端示例
1 | // 创建事件循环组 |
4.4 Netty客户端示例
1 | EventLoopGroup group = new NioEventLoopGroup(); |
总结
通过本文,咱们了解了网络编程中的核心概念:
- 五种IO模型:阻塞IO、非阻塞IO、IO复用、信号驱动IO和异步IO
- Java中的三种IO模型:BIO、NIO和AIO
- Reactor模式:单线程、多线程和主从多线程模型
- Netty框架的核心组件和基本使用
Netty不仅简化了网络编程,还提供了高性能的网络通信能力,是Java开发者进阶的必备技能。掌握了Netty,你就掌握了构建高性能网络应用的钥匙!
你问我Netty有多重要?看看这些使用Netty的知名项目就知道了:Dubbo、Elasticsearch、Hadoop、Spring WebFlux等等。它们的共同点就是:高并发、高性能、高可靠性。
学习Netty,咱们打工人的技术栈将更加完整,面试和实际工作中也会更有竞争力,这也为后面的RPC之路悄然埋下了伏笔。所以,这就开始咱们的RPC之旅吧!


