
从零开始的RPC开发旅程-框架设计与核心协议篇 0x01
从零开始的RPC开发旅程-框架设计与核心协议篇 0x01
“好的开始是成功的一半,而一个优雅的协议设计则是RPC框架的灵魂。” —— 沃兹基索德
万恶之源:为什么需要RPC框架?
记得那是一个普通的下午,咱们正在为一个分布式系统设计服务间的通信方案。面对复杂的网络环境和性能要求,我开始思考:为什么现有的RPC框架总是让咱们觉得不够”顺手”呢?要么太重,要么太轻,要么扩展性差,要么性能不够理想。
“为什么不自己设计一个RPC框架呢?一个既轻量又高性能,既易用又可扩展的框架。” —— 海斯涡
就这样,Aki-RPC的旅程开始了。(耶~~
1.第一步:协议设计
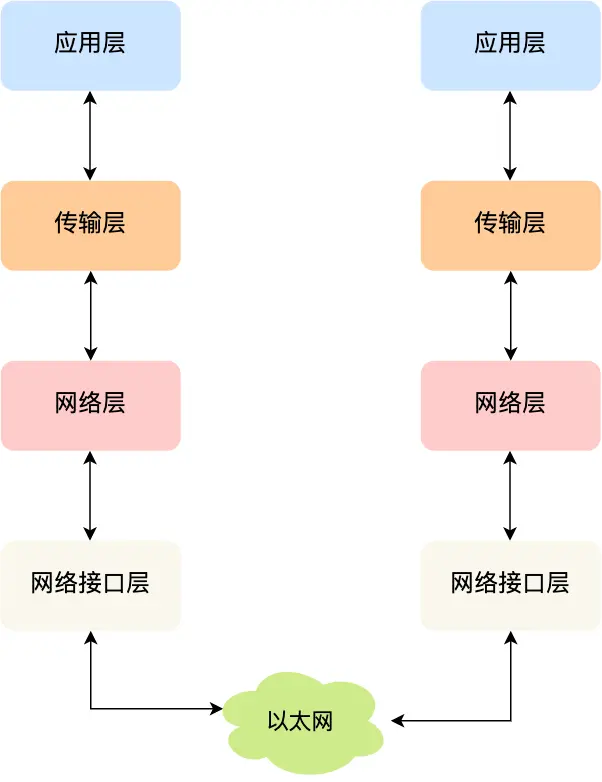
首先咱们要做的,就是设计一个RPC协议。不过在设计自定义协议前,咱们最最最先需要思考的是:应该如何设计一个既高效又可靠的通信协议?这不得不提起TCP/IP协议的设计理念——分层和模块化。
首先什么是TCP/IP 协议?他的分层和模块化又是什么?
TCP/IP协议的设计采用了分层结构,主要分为以下四个层次:
应用层:负责处理应用层协议,例如HTTP、FTP等。在RPC中,这一层是服务提供者和消费者交互的地方,包含了业务逻辑的处理。
传输层:确保数据能够可靠传输到目标主机。常见的协议如TCP和UDP,保证了数据的顺序和可靠性。
网络层:负责数据包的路由选择,确保数据能够通过正确的路径传输。常用协议如IP协议,负责地址分配与数据包路由。
网络接口层:也叫链路层,负责处理物理连接,确保数据能在物理介质中传输,例如以太网、Wi-Fi等。
TCP网络栈通过这种分层结构,每一层都有明确的职责,能够有效降低系统的复杂性,并提供灵活的扩展空间。
那么,RPC属于哪一层,它的任务应该是什么呢?
个人认为,RPC框架的定位在于传输层和应用层之间。它并不直接处理数据的路由与物理传输(这些工作交给底层的TCP/IP协议来完成),也不单纯是业务逻辑的处理者。RPC的任务是在应用层之间实现一个透明、可扩展的远程调用机制。
从设计上讲,RPC框架的核心任务是提供一个简洁、可扩展、可靠的远程调用接口,使得不同机器或服务间的通信不再依赖于底层的复杂网络细节,而是通过规范化的接口来简化开发者的操作。它就像是架设在网络和应用之间的一座桥梁,让跨越不同机器的服务能够像本地调用一样便捷
相比于传输层的TCP,RPC提供了更高层次的抽象,简化了远程过程调用的操作,避免了开发者直接与网络通信细节打交道;相比应用层的HTTP,它则更专注于服务间的高效通讯,通常使用二进制协议,比HTTP的文本协议更轻量、速度更快。附言:
RPC最早由谷歌推出的gRPC并广泛应用于现代微服务架构中。它通过引入HTTP/2协议,提供了高效的通信和流控制,解决了传统RPC的性能瓶颈。虽然咱们通常将RPC与应用层协议分开,但RPC的底层实现实际上也可以依赖HTTP协议。例如,gRPC就可以使用HTTP/2进行数据传输,借助其多路复用和更低延迟的特性。这种现象的本质原因在于RPC设计的灵活性,它并不是一种协议,而是一种规范,能够根据需求在不同的协议层面实现。总而言之,RPC作为一种现代的远程调用框架,旨在为开发者提供一种简洁、高效且可靠的分布式系统通信方式。
所以,我们应该从哪里开始设计一个自定义的RPC框架呢?
说实话,市面上RPC框架多如牛毛:gRPC、Dubbo、Thrift…各有各的特点。但问题也很明显:
- 学习成本高 —— 看看Dubbo的文档厚度,那简直是一本”葵花宝典”
- 配置繁琐 —— 动不动就是几十个XML配置,改一个参数要翻半天文档
- 依赖重 —— 引入一个框架,结果带来一堆传递依赖,项目瞬间胖了10MB
- 定制难 —— 想改个序列化方式?抱歉,得改源码
最关键的是,用别人的框架永远不如自己写的爽!(程序员本质暴露了😂)
RPC的核心问题是什么?是让”远程调用像本地调用一样简单”。而实现这一点的第一步,就是设计一个高效、可靠的传输帧(Transport Frame)。
为什么传输帧如此重要?想象一下没有传输帧的场景:
- 客户端发送:”我要调用userService.getUser方法,参数是userId=123”
- 服务端收到:”我要调用userService.getU”(啊哦,数据不完整,调用异常哔哔哔)
- 服务端又收到:”ser方法,参数是u”(继续等待)
- 服务端又收到:”serId=123”(这才完整)
这就是典型的TCP粘包/拆包问题,虽然TCP协议本身可靠、不粘包,但是基于TCP传输层实现的应用层协议,不能避免其面向流传输的粘包问题!没有一个良好的传输帧设计,服务端根本无法判断一个完整的请求从哪里开始,到哪里结束。就像在没有标点符号的文章中阅读一样痛苦。
而一个优秀的RPC传输帧通常包含以下核心组成部分:
- 魔法数(Magic Number) —— 用于快速识别帧的开始,就像HTTP的”HTTP/“一样。这能帮助我们在混乱的字节流中定位到属于自己的数据包。没有它,就像在拥挤的火车站没有站牌,你根本不知道该去哪个站台。
- 版本号(Version) —— 协议会进化,今天v1,明天可能就v2了。版本号确保双方”说同一种语言”。没有它,就像两个人一个说中文一个说英文,鸡同鸭讲。
- 消息长度(Full Length) —— 明确指出这个消息有多长,解决TCP粘包/拆包问题的关键。没有它,就像收到一封没有结尾的信,永远不知道什么时候读完。
- 消息类型(Message Type) —— 请求?响应?心跳?错误?不同类型的消息处理方式不同。没有它,就像收到一个包裹却不知道是快递还是外卖。
- 序列化类型(Codec) —— JSON?Protobuf?Hessian?告诉接收方如何”解读”消息体。没有它,就像拿到一本书却不知道是中文还是俄文。
- 压缩类型(Compress) —— GZIP?Snappy?数据是否被压缩,如何解压?没有它,就像收到一个压缩包却不知道用什么软件解压。
- 请求ID(Request ID) —— 异步RPC中,请求和响应通过ID匹配。没有它,就像在餐厅点餐却没有取餐号,永远不知道哪份餐是你的。
- 消息体(Body) —— 真正要传输的数据,可能是序列化后的请求参数或响应结果。这就是信件的正文,没有它整个传输就没有意义。
设计传输帧就像设计一个信封 —— 看似简单,却关系到信件能否安全、完整地送达目的地。一个好的信封设计,可以让信件在漫长的旅途中不被损坏,不被篡改,不被错送,最终准确无误地送到收件人手中。
所以,让我们开始吧~!
1.1 消息帧结构设计
“如果说魔法数是框架的身份证,那么消息帧结构就是框架的骨架。它决定了数据如何在网络中流动,如何被解析,如何被处理。” —— 布兹道斯赦
在设计消息帧结构时,咱们参考了HTTP协议的设计思路,但做了很多优化:
1 | 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
这个设计考虑了以下几个关键点:
- 固定长度的头部,便于快速解析
- 预留扩展位,为未来升级做准备
- 支持多种序列化和压缩方式
- 请求ID用于追踪和匹配请求响应
1.2 魔法数的选择
1 | public static final byte[] MAGIC_NUMBER = {(byte)'k',(byte)'i',(byte)'r',(byte)'a'}; |
选择魔法数时,咱们考虑了很多因素:
- 要有辨识度,不能太普通
- 要容易记忆
- 要能体现框架的特点
- 要能让人一眼就记住,就像”Hello World”一样深入人心
最终选择了”kira”作为魔法数,不仅因为它容易记忆,还因为它暗示着这个框架的”闪耀”特性 ✨
序列化与压缩的选择
“序列化就像是在打包行李,压缩则是在打包好的行李上再套一个压缩袋。选择什么样的打包方式,决定了行李的大小和打开的速度。” —— 一个正在比较各种序列化方案的开发者
在序列化方案的选择上,咱们对比了多种方案:
- JSON:可读性好,但性能较差
- Protobuf:性能好,但需要预编译
- Hessian:跨语言支持好,但性能一般
本次咱们选择Protostuff实现,因为:
- 不需要预编译
- 性能接近Protobuf
- 支持动态类型
- 内存占用小
1 | public class ProtostuffSerializer implements Serializer { |
在压缩方案上,选择了GZIP,因为:
- 压缩率高
- CPU消耗适中
- 广泛支持
实现过程中的思考
TCP粘包/拆包:数据传输中的”小插曲”
你有没有遇到过这种情况:明明发送了两条完整的消息,对方却只收到了一条半?或者发了一条消息,对方却收到了两次?这就是网络通信中著名的”粘包/拆包”问题!
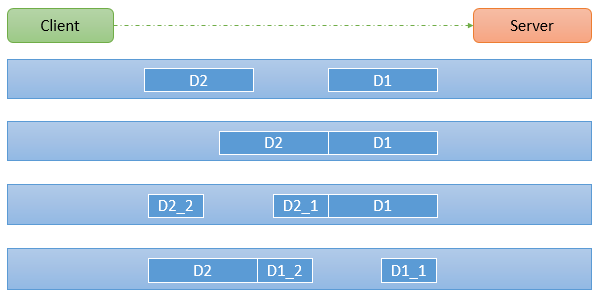
为什么会发生粘包/拆包?
造成这一现象的罪魁祸首主要有三个:滑动窗口、MTU限制和Nagle算法。它们本是TCP提高传输效率的法宝,却”阴差阳错”地引发了应用层的烦恼。
1. 滑动窗口:流量控制的”双刃剑”
滑动窗口是TCP流量控制的核心机制,就像是发送方和接收方之间的”约定”:
1 | 接收方:嘿,我的缓冲区只能放100个字节,你别一次发太多! |
粘包现象:假设每个完整消息是256字节,但接收方处理太慢,多个消息都堆积在了接收缓冲区里。当应用程序来取数据时,可能一次性读取到了多个消息,这就是粘包。
拆包现象:如果发送方要发256字节,但接收窗口只剩128字节,发送方只能先发128字节,等确认后再发剩下的,一个完整消息就被”拆”成了两半。
2. MSS/MTU限制:网络包裹的”尺寸限制”
想象一下邮局的规定:每个包裹不能超过10公斤,如果你要寄15公斤的东西,就必须分成两个包裹。网络传输中的MTU和MSS就是这样的”尺寸限制”。
MTU (最大传输单元):数据链路层对一次能传输的数据大小的限制,通常为1500字节。
MSS (最大分段大小):TCP数据部分的最大长度,计算公式为:
MSS = MTU - IP头(20字节) - TCP头(20字节) = 1460字节

需要注意的是MSS表示的一次可以发送的DATA的最大长度,而不是DATA的真实长度。
当你的数据超过MSS时,TCP协议会自动将其分片发送,这就造成了拆包。
奇怪知识:本地回环地址(127.0.0.1)的MTU竟然高达65535字节!这是因为本地测试不经过网卡,不受1500字节的限制。难怪本地测试总是一切正常,一上线就出问题…
3. Nagle算法:网络效率的”守护者”
Nagle算法就像是公交车司机:宁可多等几个乘客上车,也不愿意车子只载一两个人就发车,这样才能提高效率。
在网络传输中,每发送一个包都会带上TCP头和IP头(总共约40字节)。如果数据本身只有1字节,却要额外附加40字节的头信息,这种4000%的开销简直是灾难!
Nagle算法的核心规则:
如果数据达到MSS大小,立即发送
如果包含FIN标志(关闭连接),立即发送
如果设置了TCP_NODELAY选项,立即发送
如果所有已发送小数据包都收到了确认,可以发送
上述条件都不满足,但超过200ms,也会发送
这个算法会尽量攒够一定量的数据再发送,减少网络中的小包数量,但也因此可能导致粘包。
如何解决粘包/拆包问题?
既然了解了”病因”,就该谈谈”药方”了!
在应用层,我们通常有以下几种解决方案:
固定长度:每条消息固定长度,不够的部分用空字符填充
分隔符:在消息之间插入特殊分隔符,如HTTP协议中的空行
长度字段:消息头部增加长度字段,明确告知接收方消息有多长
自定义协议:设计更复杂的协议,包含更多元信息
在实际开发中,Netty框架提供了多种编解码器来解决这个问题,比如LengthFieldBasedFrameDecoder就是基于长度字段的解码器,能够优雅地处理粘包/拆包问题。
TCP尽力保证数据的可靠传输,但并不关心数据的”语义完整性”,这就需要应用层自己来把握了!
如何设计编解码器?
“TCP的粘包问题就像是在一条传送带上,多个包裹被粘在了一起。我们需要一种方法来识别每个包裹的边界。” —— 一个正在解决粘包问题的开发者
在实现过程中,最让咱们头疼的是TCP的粘包问题。经过多次尝试,咱们采用了Netty的LengthFieldBasedFrameDecoder:
编码器
1 | // 编码器 |
解码器
1 | // 解码器 |
这样,解码和编码都可以按照预设好的位数切分和解析啦!
下一步计划
协议设计只是开始,接下来还需要:
- 实现服务注册与发现
- 设计负载均衡策略
- 完善监控和日志
- 优化性能
结语
设计一个RPC框架的协议层,就像是在设计一座桥梁的基础。它需要足够的坚固来承载未来的扩展,也需要足够的灵活来适应各种场景。在这个过程中,咱们学到了很多,也遇到了很多挑战。但正是这些挑战,让这个项目变得更有意义。
“好的协议设计,就像好的代码一样,是优雅的,是简洁的,是经得起时间考验的。” —— 一个仍在路上的开发者


