
Go日志解析-xx科技笔试题解
Go日志解析-笔试题解
此次笔试题目要求我们开发一个高性能的日志解析工具,能够从40万行标准Go日志中提取三种关键信息块:
- 数据竞争问题(Data Race)信息
- Panic异常信息
- 运行时间超过20分钟的goroutine信息
关键挑战点:
- 需要通过HTTP下载远程日志文件
- 使用正则表达式精确匹配各类日志块
- 构建状态机处理复杂的panic日志格式
- 代码需通过并发测试(10个并发协程同时执行)
- 仅允许使用Go标准库
- 结果必须精确通过字符串断言测试
解题思路
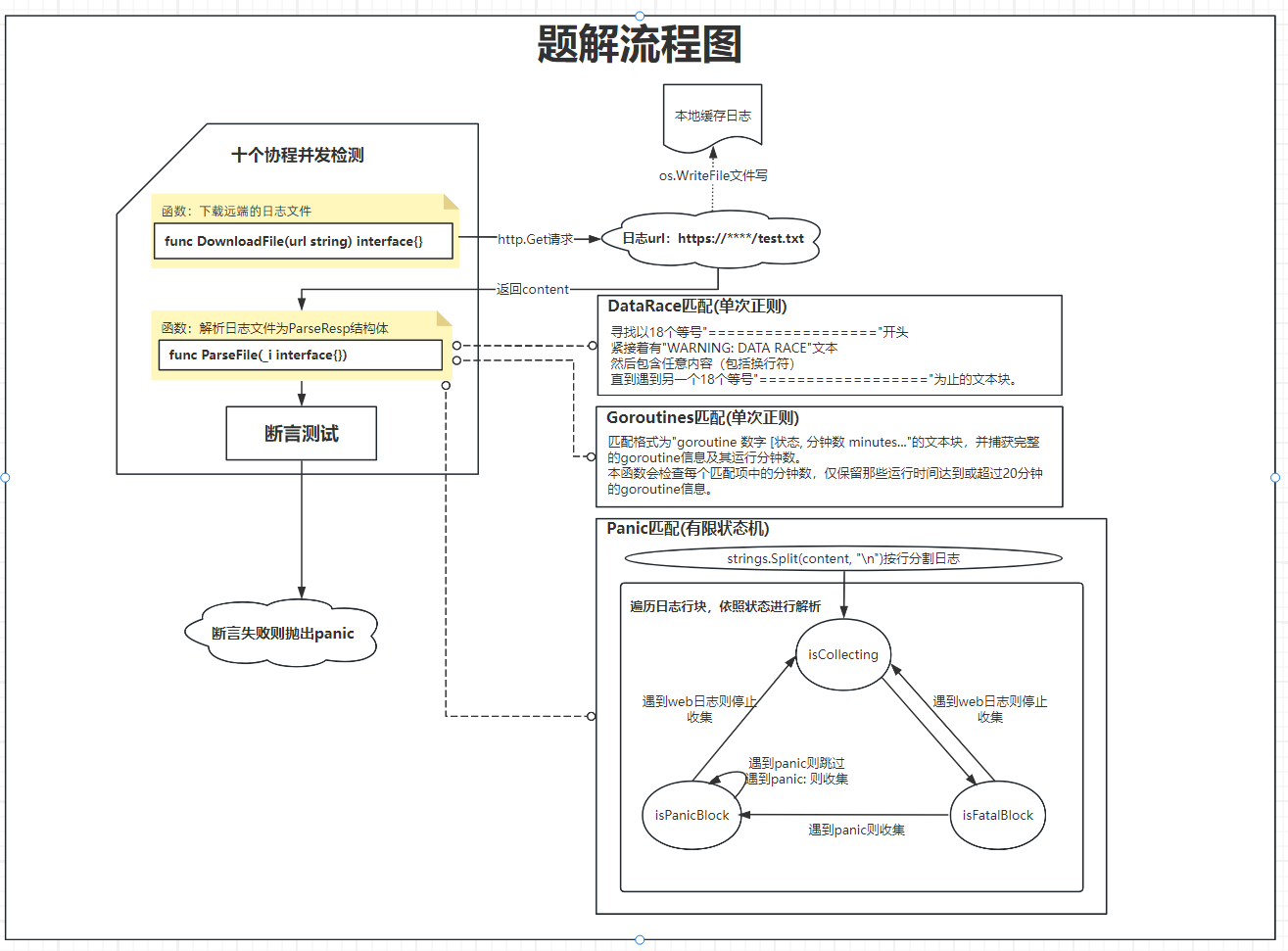
解析工作分为三个核心部分:
1. 数据竞争信息提取
使用正则表达式匹配以==================开头,包含WARNING: DATA RACE的日志块,一直到下一个==================结束。这些块包含了哪些goroutine之间发生了数据竞争。
2. 长时间运行goroutine提取
使用正则表达式匹配包含运行时间信息的goroutine日志,提取出运行超过20分钟的goroutine信息。
3. Panic信息提取
这里我实现了一个状态机来处理panic信息:
- 三个状态标志:
isCollecting(是否正在收集)、isFatalBlock(是否fatal error块)、isPanicBlock(是否panic块) - 逐行处理日志,遇到特定模式(如”panic:”、”fatal error:”)时启动收集
- 跳过普通日志行(INFO/DEBUG/WARN等)
- 在收集状态下将相关内容添加到结果中
思路难点
设计正则表达式
1
2
3
4
5// Data Race匹配
re := regexp.MustCompile(`(?s)==================\s*\nWARNING: DATA RACE[\s\S]*?==================`)
// 长时间运行goroutine匹配
re := regexp.MustCompile(`(?s)(goroutine \d+ \[[^,]+, (\d+) minutes[^\n]*[\s\S]*?)(?:\n\n|\z)`)状态机设计
为处理复杂的Panic信息,设计了一个基于状态的解析器,能够正确区分不同类型的错误信息并处理边界情况。1
通过结果
代码通过了10个并发协程的测试,成功解析出所有样例数据。从运行日志可以看出,日志下载和解析功能正常工作:
1 | 日志已保存到: testLog_1745531548235076900_44792.txt |
答题总结
本次题目要求我们实现一个健壮的日志解析系统,关键挑战在于:
- 精确的模式匹配:使用正则表达式和状态机正确识别各种日志格式
- 边界情况处理:处理换行符、格式一致性等细节问题
- 并发安全:确保代码在多goroutine并发执行时正确工作
解决此类问题的关键是深入理解Go日志的结构特点,并设计合适的状态机来处理复杂格式。同时,在处理文本时需要特别注意格式一致性和换行符等细节问题,这些往往是测试用例失败的主要原因。(熬夜debug的血泪)
此题也展示了Go语言标准库在文本处理方面的强大能力,特别是正则表达式和字符串处理功能,为解决此类问题提供了良好支持。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Aki-zora!

评论

